
DuckDB as a compaction work horse | Readings
As developers, we often encounter the challenge of managing large datasets efficiently. My recent experience with the public transportation data of Porto, Portugal, served as good test for optimizing storage costs without compromising data accessibility.
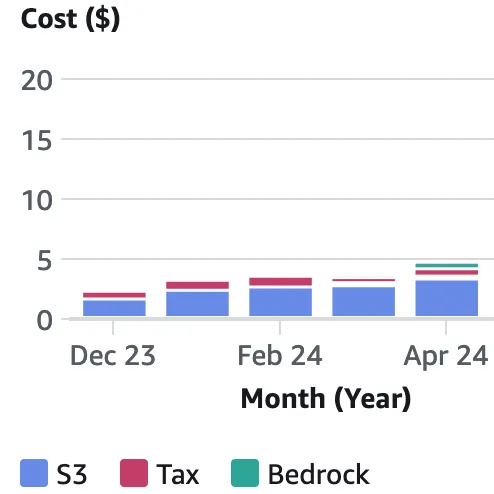
Over seven months, from November to May, I collected real-time data, culminating in a 150 GB dataset. This growth naturally led to increased storage costs, prompting me to explore data compaction and S3 tiering strategies to reduce my 5$ monthly expense.
The Compaction Strategy
DuckDB’s seamless integration with AWS S3 through the secret manager facilitated the compaction of parquet files, which are known for their efficiency in storing large volumes of data.
Here’s a glimpse into the SQL magic that made it all happen:
-- Setting up access to S3 via DuckDB's secret manager
CREATE SECRET (
TYPE S3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY',
REGION 'eu-central-1'
SCOPE 's3://porto-realtime-transport/' --This is the scope of the secret, necessary for those with more than 1 aws account
);
-- Compacting and exporting data with DuckDB
copy
(select * from 's3://porto-realtime-transport/file_data/2024/1/*.parquet')
to 's3://porto-realtime-transport/file_data/2024/202401.parquet'
(compression ZSTD);
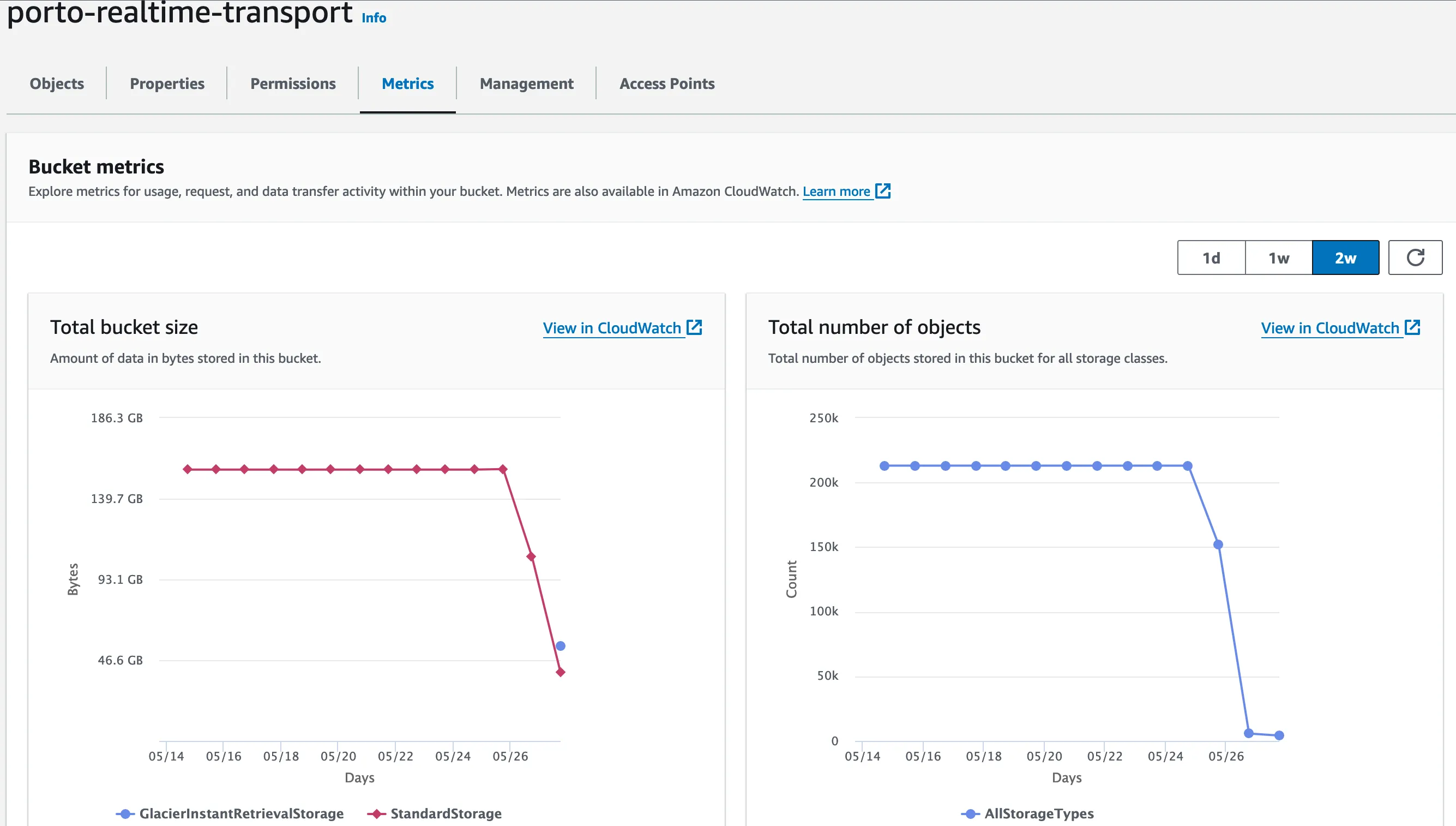
By running this script for each month, I achieved a remarkable 75% reduction in storage size and a 98% decrease in the number of files.
Cost Calculations and Further Savings
Initially, the cost savings looked promising, reducing monthly expenses from approximately $4 to $0.98. However, recognizing that the data was primarily for historical reference, I transitioned to Glacier Instant Retrieval storage, slashing costs further to just $0.20 per month.
Key Takeaways and Best Practices
The process was straightforward, but it highlighted the importance of considering egress costs. A more cost-effective approach would have been to run the compaction on an EC2 instance rather than a local machine, avoiding the additional charges associated with data retrieval.
Although this seems like a simple operation, it shows how good some data engineering is nowadays. Hope this is useful for you!
Readings
- Introducing GitHub Copilot Extensions: Unlocking unlimited possibilities with our ecosystem of partners - The GitHub Blog by Mario Rodriguez: Super interesting to see these extensions! It enables so many use cases and could be a productivity booster
- Google Brings Gemini Nano to Chrome to Enable On-Device Generative AI - InfoQ by Sergio De Simone: Interesting to see biotin support for local llm. Hopefully they’ll be working making this a browser standard and not a chrome exclusive
- S3 Is Showing Its Age - by Chris Riccomini by Chris Riccomini: A critique of S3 lack of features. Although I truly love the concept of the lakehouse and I think it’s possible to get
- Hacking our way to better team meetings | All Things Distributed by Werner Vogels
Goal of the week
Just scheduled my first AWS exam for the 26 of July! Have some time to study for it and a little bit before going on vacations! It will be fun 😅
- Trim on the reading list
- Test the GPT4-O interface